| Imputation | Bias (CR) | Coverage (CR) | Bias (SR) | Coverage (SR) |
|---|---|---|---|---|
| normal (-3, -3) | -0.53 | 0.998 | -1.12 | 0.492 |
| normal (0, 0) | -0.12 | 1.000 | -0.71 | 0.886 |
| normal (3, 3) | 0.27 | 1.000 | -0.32 | 0.998 |
| tmvn (1, 5) | -0.04 | 1.000 | -0.01 | 1.000 |
| uniform (0, 0) | -0.16 | 1.000 | -0.75 | 1.000 |
Missing outcomes imputation in bivariate meta-analysis
Padova EMPG Conference, 3 September 2025
Multivariate meta-analysis
“[…] many clinical studies have more than one outcome variable; this is the norm rather than the exception. These variables are seldom independent and so each must carry some information about the others. If we can use this information, we should.” (Bland 2011)

Missing data
Rubin (1976) introduced a foundational framework distinguishing missing data mechanisms: Missing Completely At Random (MCAR), Missing At Random (MAR), Missing Not At Random (MNAR)
These mechanisms differ from missing data patterns, which refer to the observed structure of which values are present or absent.
Patterns = “What” is missing
Mechanisms = “Why” it is missing

Missing Completely At Random
MCAR: Missingness is unrelated to observed or unobserved data. The missing sample is a random subsample.
\[ P(M \mid Y, \phi) = P(M \mid \phi) \]

Missing At Random
MAR: Missingness depends on observed variables.
\[ P(M \mid Y, \phi) = P(M \mid Y_{obs}, \phi) \]

Missing Not At Random
MNAR: Missingness depends on unobserved variables (or both).
\[ P(M \mid Y, \phi) = P(M \mid Y_{mis}, \phi) \]
\[ P(M \mid Y, \phi) = P(M \mid Y_{obs}, Y_{mis}, \phi) \]

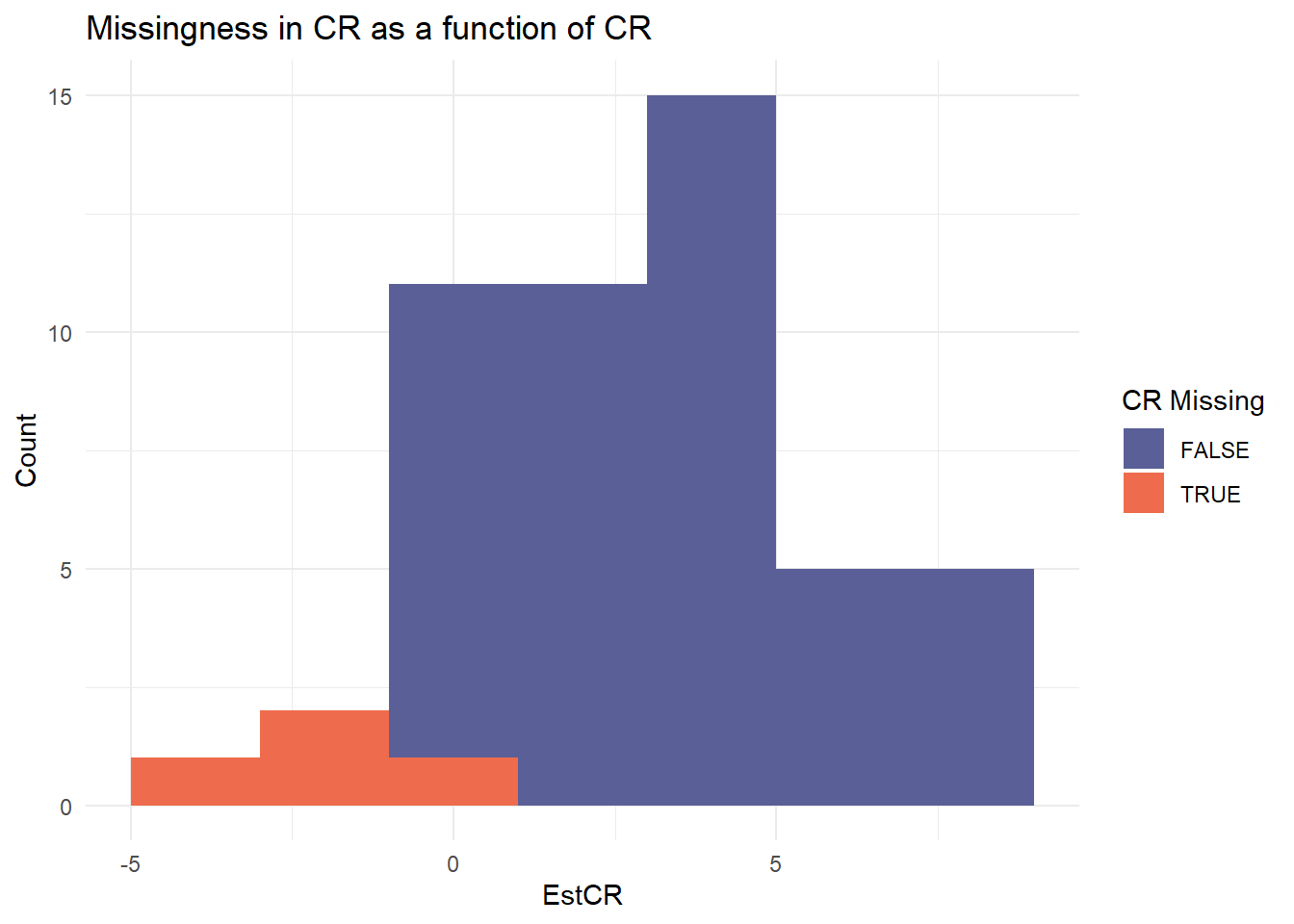
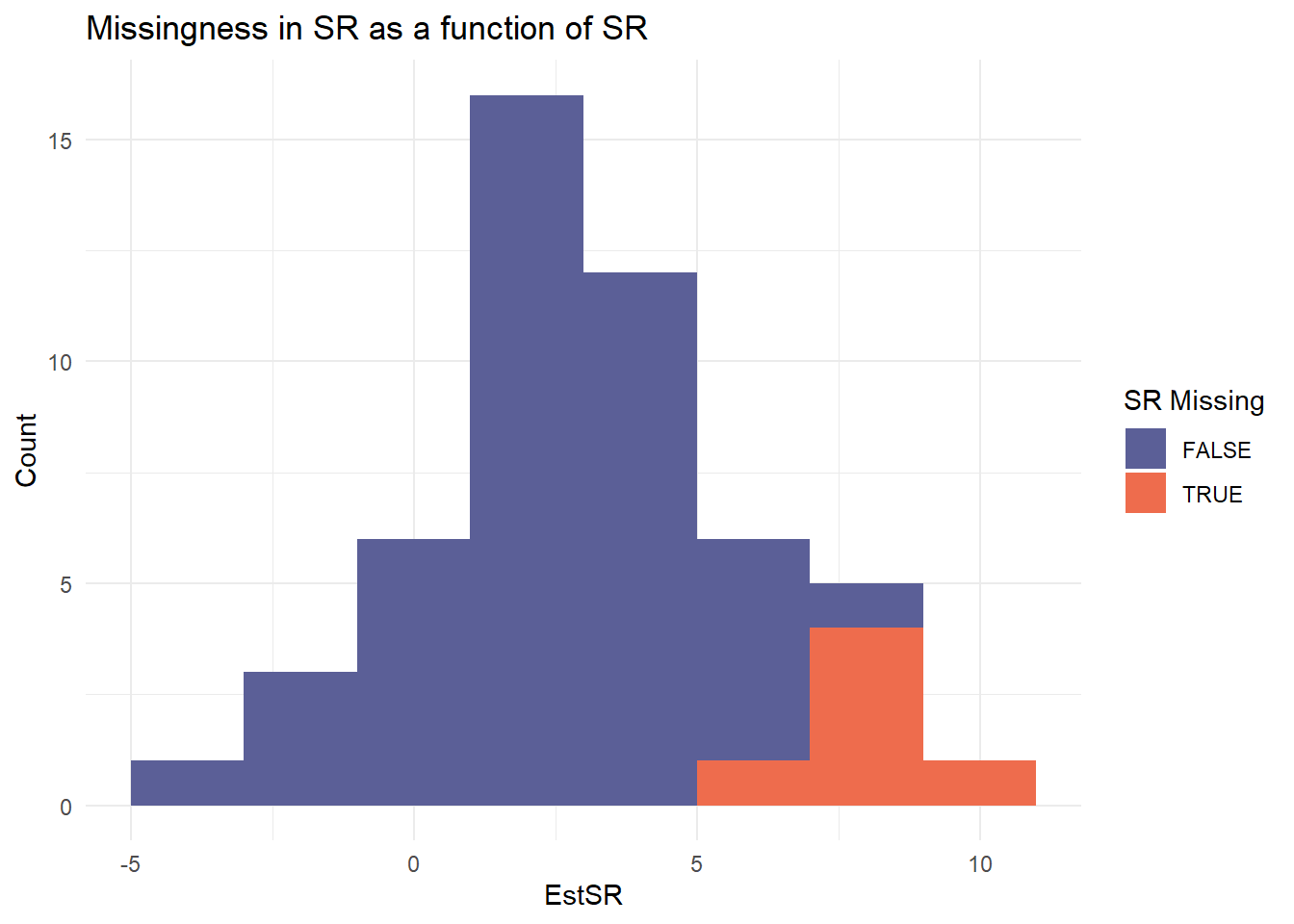
MNAR mechanism
- Missingness based on effect size estimates:
- CR: more likely missing when treatment effect is low
- SR: more likely missing when treatment effect is high
- Conflict resolution: keep the one furthest from the mean
 |
 |
Estimated CR with 95% CI

Estimated SR with 95% CI

Application to real data
Cuijpers et al. (2010) collected data from 48 studies that measure depression on both a clinician rating (HRSD; Hamilton (1960)) and self-report scale (BDI; Beck et al. (1961)). The meta-analysis highlights a substantial difference between the patients’ and clinicians’ evaluations of depression, in favor of the clinician rating.

Impute missing outcome measures using the package missmeta

Plot the results
