# A tibble: 6 × 7
Study N EstCR SECR EstSR SESR Cor.ws
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Arean et al. (1993)a 49 -13.2 1.62 -5.5 1.89 0.7
2 Ayen and Hautzinger (2004)a 21 NA NA -14 1.75 NA
3 Bowers et al. (1993) 16 -3.1 1.52 -5.1 2.83 0.7
4 Bowman, Scogin, and Lyrene (1995)a 20 -7.1 3.17 -10.6 4.86 0.7
5 Brand and Clingempeel (1992) 53 -4.81 1.81 -2.6 2.58 0.7
6 Carpenter et al. (2008) 24 2.10 4.04 NA NA NA Missing outcomes imputation in bivariate meta-analysis
Psicostat Hands-On, 29 May 2025
MCAR
MCAR: Missingness is unrelated to observed or unobserved data. The missing sample is a random subsample.
\[ P(M \mid Y, \phi) = P(M \mid \phi) \]

MAR
MAR: Missingness depends on observed variables.
\[ P(M \mid Y, \phi) = P(M \mid Y_{obs}, \phi) \]

MNAR
Missingness depends on unobserved variables (or both).
\[ P(M \mid Y, \phi) = P(M \mid Y_{mis}, \phi) \]
\[ P(M \mid Y, \phi) = P(M \mid Y_{obs}, Y_{mis}, \phi) \]
 |
 |
What if outcomes are missing not at random?

Missingness Mechanism (MNAR)
- Logistic models on effect size estimates
- Missingness depends on CR (positive bias) or SR (negative bias)
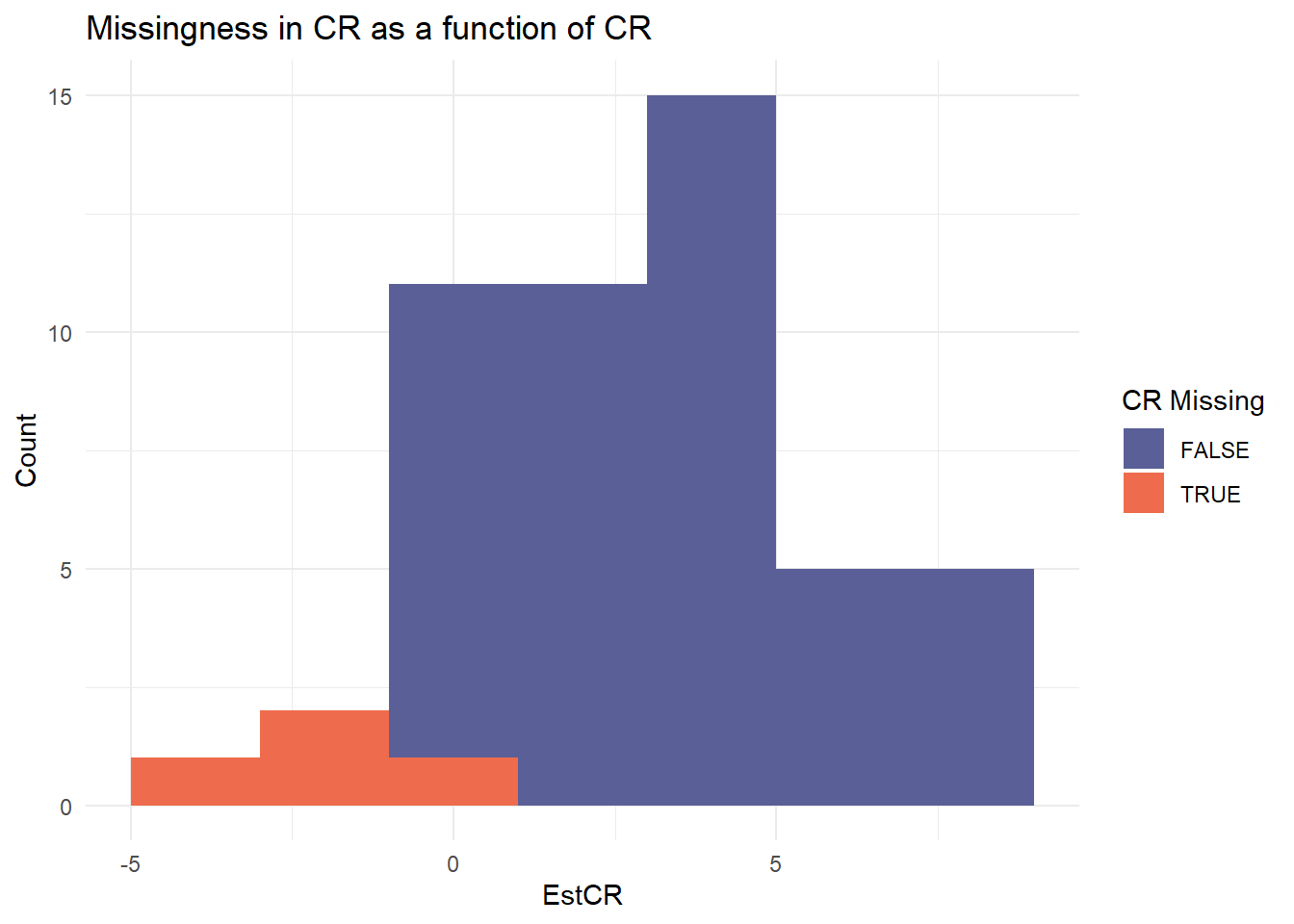 |
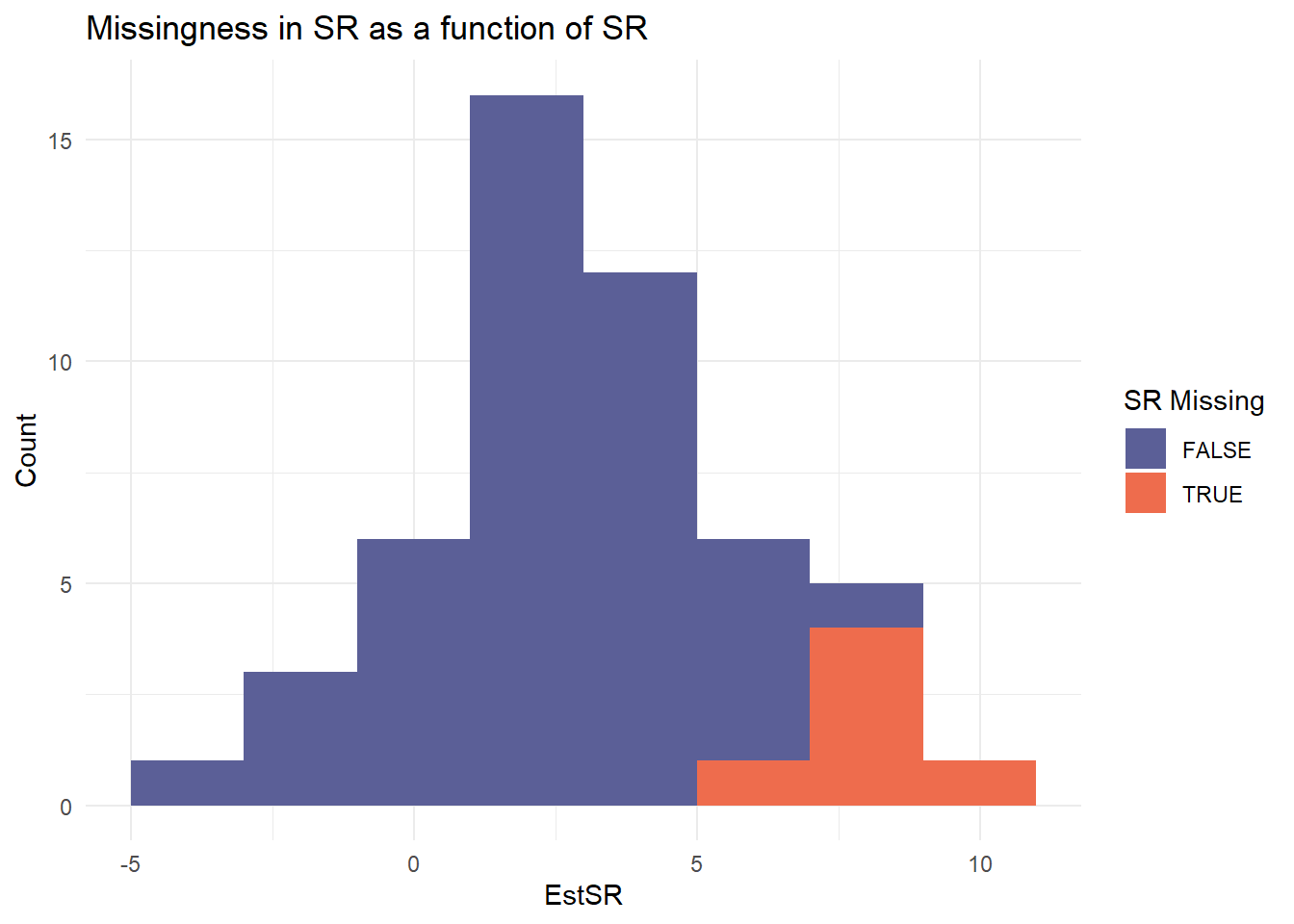 |
Cuijpers et al. (2010)
Cuijpers and colleagues collected data from 48 studies that measure depression on both a clinician rating (HRSD) and self-report scale (BDI).
The meta-analysis highlights a substantial difference between the patients’ and clinicians’ evaluations of depression, in favor of the clinician rating.

What if the outcomes are MNAR?
Then we imputed the missing HRSD and BDI outcomes with random draws from selected distribution (uniform, multivariate normal, normal) to reflect different assumptions on the missingness mechanisms.
The goal is to explore if the results are robust across assumptions (more or less conservative).
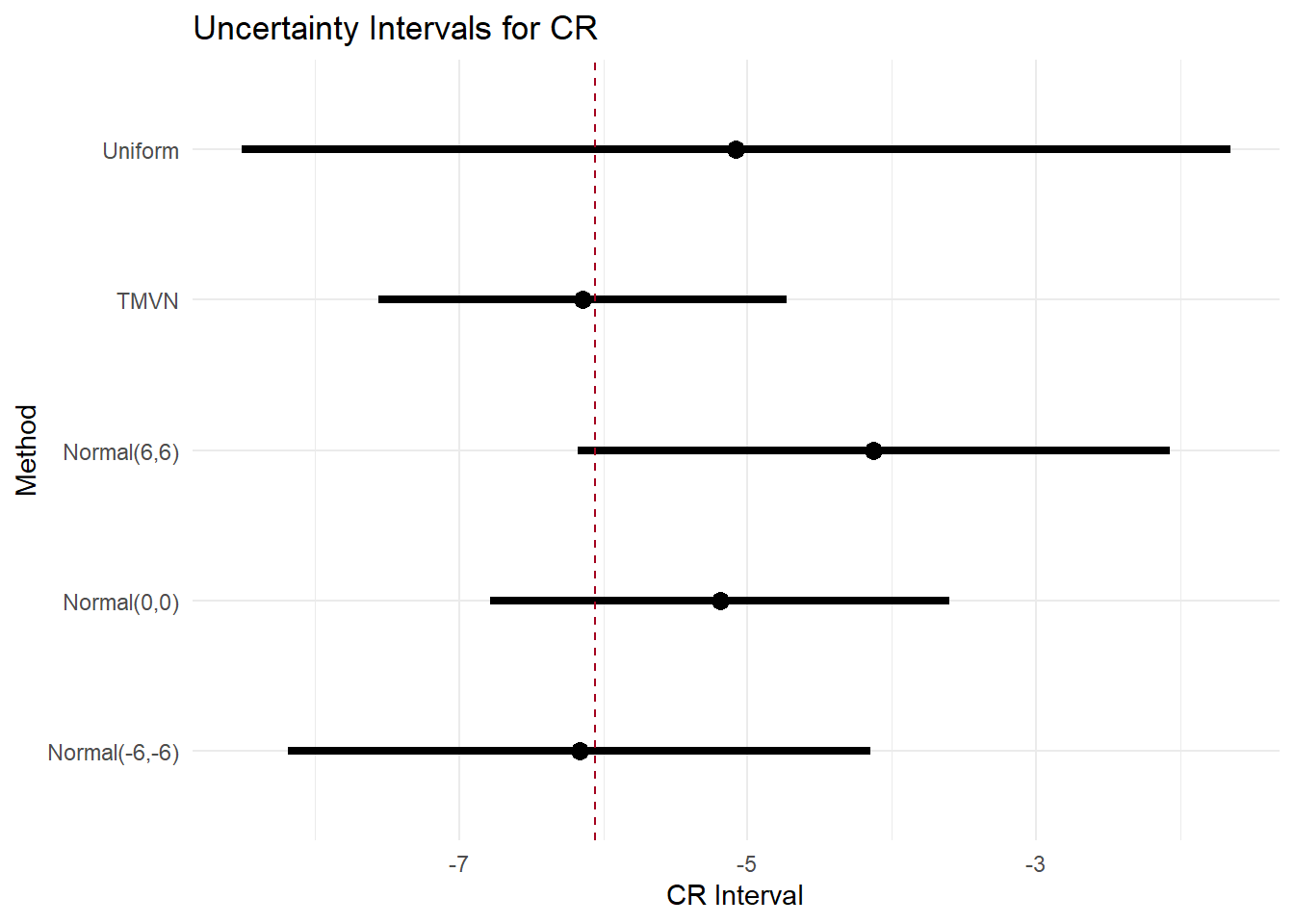 |
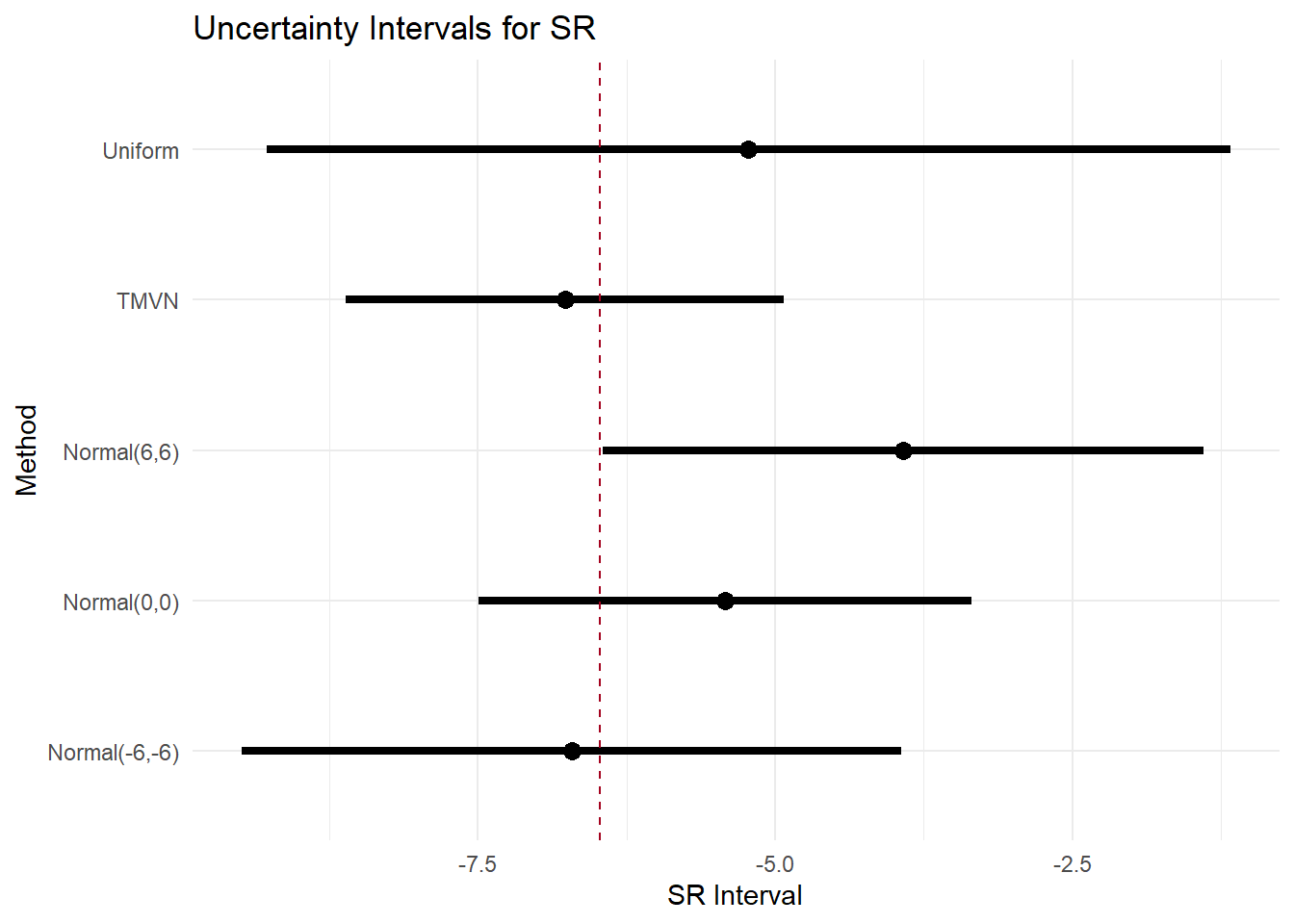 |
SPOILER!1!!1
It will be (soon) available an R package that allows the user to perform multivariate meta-analysis choices with different packages and choose her favourite distributions!
Grazie mille!
